Localization in Invoices
by Ottimate Editors
In this blog post we will explain how we do localization for invoice header fields. Examples of header fields include Invoice Number, Date, Tax and Total.
Everyday we at Ottimate process invoices from more than 60K vendors. These include invoices from major food distributors, liquor vendors, produce/meat suppliers,and also boutique farm to table vendors. The sheer number of variations in invoice formats- coupled with uncertainty because of image and OCR quality- makes localizing headers at our scale a challenging problem. As a result, we need a system that can generalize to all these various invoice formats.
We have seen tremendous progress in object localization using Deep Learning. Given the amount of training data we had, we decided to tackle the problem using some of the state-of-the-art deep learning techniques. We will first talk about the different input types we used and the model architecture used to train a model.
Types of Input Data for the Model
Character Grid Data Structure
At Ottimate, we have been leveraging powerful OCR systems, but they don’t have a feature of localizing the field of interest. On the other hand, deep learning techniques for localization have improved a lot recently for natural images. So we decided to move forward with a hybrid approach. We can leverage the output of a traditional OCR to train a deep learning model. For this purpose, we came up with a data structure that we called “Character Grid” (Or “CharGrid” for short). Let’s explain the CharGrid a little bit in more detail:
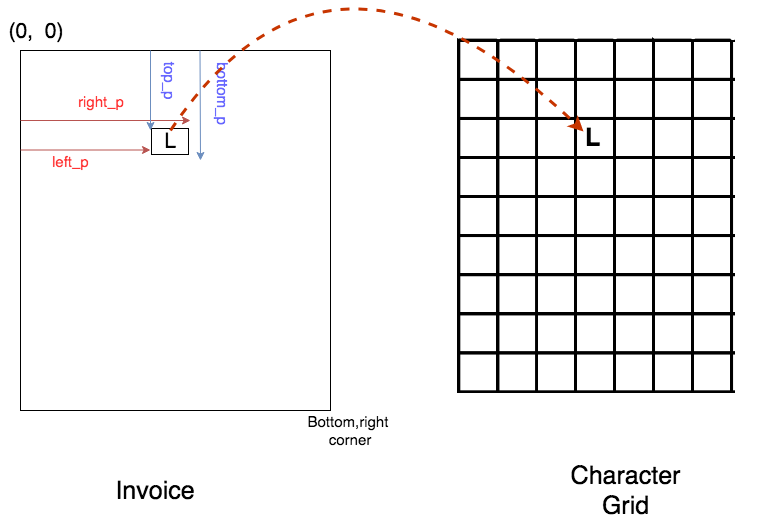
CharGrid is nothing but a matrix of characters. Each entry of the matrix is going to be an integer representing a distinct character, which are 1-hot encoded. We represent the location of a character with four floats in the invoice image:
(left_p, top_p, right_p, bottom_p)
Then, we initialize a matrix of size MxN and insert each character to the closest corresponding entry in the matrix. This matrix becomes the CharGrid.You can see an illustration below.
Some parameters of the CharGrid in our project are as follows:
-Number of rows and columns are chosen empirically by looking at how well CharGrid represents the raw image invoice. (For example if we increase the number of columns, the characters in CharGrid become very far apart from each other, and this is not desirable.)
-1-hot character encoding dimensionality consists of lowercase and uppercase letters, numbers, symbols and plus one for an unknown char.
This CharGrid data structure will be fed into the model with its first layer being an Embedding layer. We will cover this in the later sections. Below you can see an invoice image and its CharGrid.

Raw image
CharGrid is a useful representation of the invoice because we directly obtained the information about the characters and their locations. This way, the deep learning model being trained does not have to spend time learning to “read” what is in the invoice. However, raw images also contain a lot of useful information such as grids, lines, tables, font type, etc. that we are disregarding if we train the model only with CharGrid. For this reason, we thought that it is also worth training a model with raw image.
The issue with using raw image as an input to the model is that the resolution should be high enough that the model can “read” the text in the image. Below you can see an invoice image resized to 256×256. In this case a lot of textual information has been lost (you cannot read it).
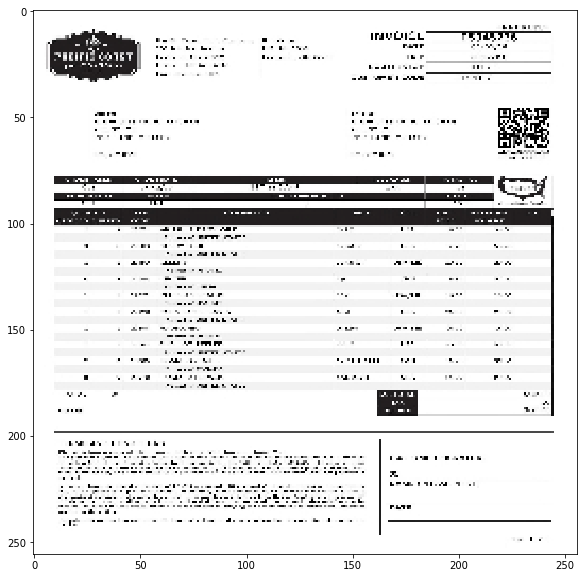
For this reason, we decided to move forward with invoice image size of 1024×1024. At this resolution, the image should contain enough textual detail.
Model Architecture and Training
In this section, we will talk about the architecture of the deep learning model we decided to train and the choice of the hyper-parameters. After that we will present the results.
Model Architecture
We approached this problem as a segmentation problem (Ex. trying to segment out the location of Invoice Total). The choice of model architecture was a U-Net like model. You can see a typical U-Net architecture.
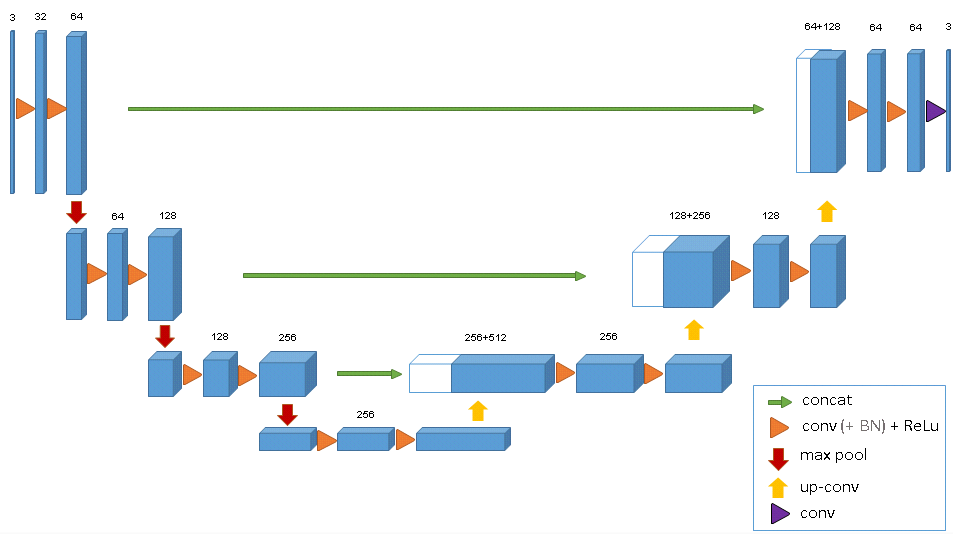
Since we are training a segmentation model with U-Net, we need to generate segmentation masks for training labels. So in our training data:
-X: Input (Either CharGrid representation or Raw Image)
-Y: Output or training labels (segmentation mask.)
In the figure below you can see a training sample pair: Raw image input and its corresponding mask label for Invoice Total. We also do the same thing for CharGrid input.
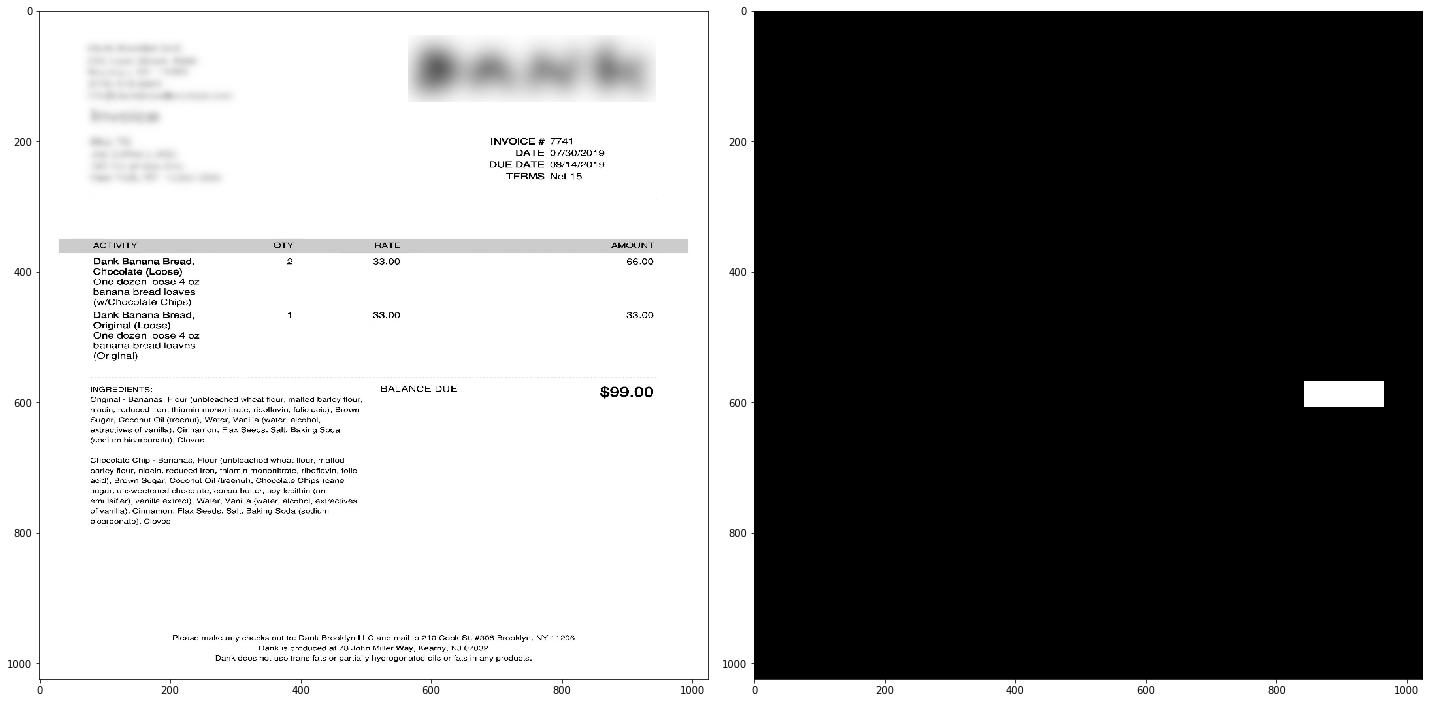
As we have mentioned in the CharGrid section, since each entry of CharGrid is actually a category (each character is a category), we need an Embedding layer as the first layer of the model when we the input is CharGrid. We created two separate models and separate training for two different input types: CharGrid and Raw Image.
Since the input shape of the model with the Raw Image is much bigger, and since it starts from the raw image without any notion of characters (unlike CharGrid), this model needs more learning “capacity”, hence more parameters. We assigned more convolution filters and more convolution blocks (roughly 2 Conv Layers + MaxPool) to the model with Raw Image input.
Training
At this point we defined two separate models: One model with CharGrid input and the other one with Raw Image input. We wanted to run an experiment to see which model performs better in terms of localization. We conducted this comparison experiment only on the Invoice Total header field. We defined our success metric to be IoU (Intersection over Union) between the prediction bounding box and the ground truth bounding box. Let’s briefly go over our experiment setup:
-Dataset: Our train-test split ratio is 0.2.
-Optimizer: Adam
-Loss Function: Dice Loss + Binary Cross Entropy Loss
Below, you can see the training in progress. After each batch, the model’s weights are updated and model’s predictions get better each time. (This is the model with CharGrid input)

Results
Let’s look at some predictions from our models.
Some predictions from the model with CharGrid input:

And some predictions from the model with Raw Image input:

CharGrid vs. Raw Image: Here we present the results on Test dataset.

We measured that the model with Raw Image input gives an average IoU roughly 0.1 higher than the model with CharGrid input but that comes with the cost of much longer training time (25 hours) due to the higher number of parameters.
Predictions on Invoices with Different Languages: We decided to try our model (the one with Raw Image input) on invoices with different languages. Below, you can see some results:
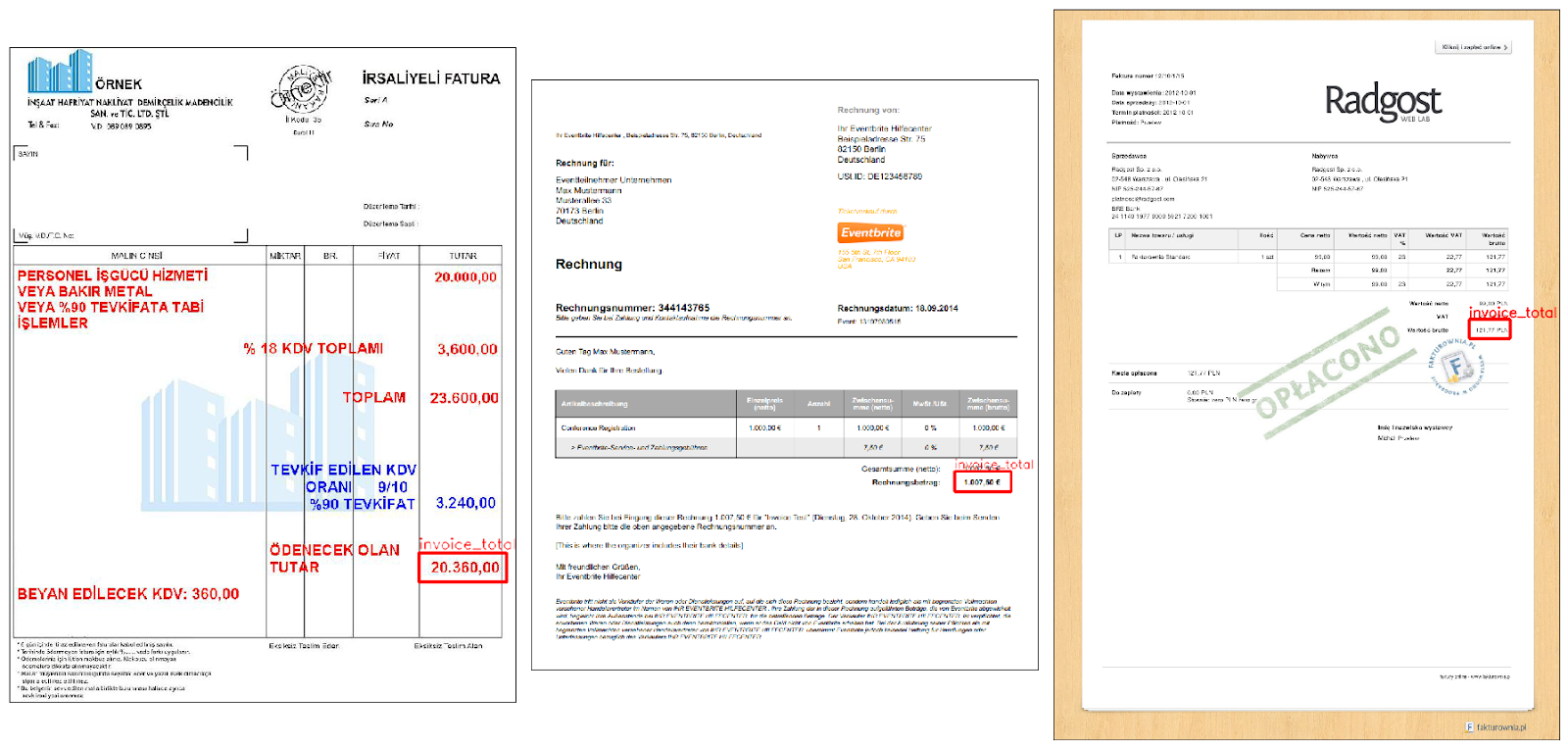
As we can see the predictions for Invoice Total are accurate even for invoices with different languages. It is an interesting result because our training data only consists of invoices with the English language.
Discussion and Future Work
Overall we trained two models: one with CharGrid input and one with Raw Image input. We compared their results on the test set. Even though the model with Raw Image input performed better on the test set, its training time is drastically higher than the model with CharGrid input because the latter requires less number of model parameters thanks to the compact invoice representation of CharGrid. In the future we are planning to make an ensemble model combining both CharGrid and Raw Image to get even better results.
Digitization of invoices does not end with header fields. There is also an even more challenging part of invoices: Line Items. In our future blog posts we will explain how we made use of deep learning for line items, as well.